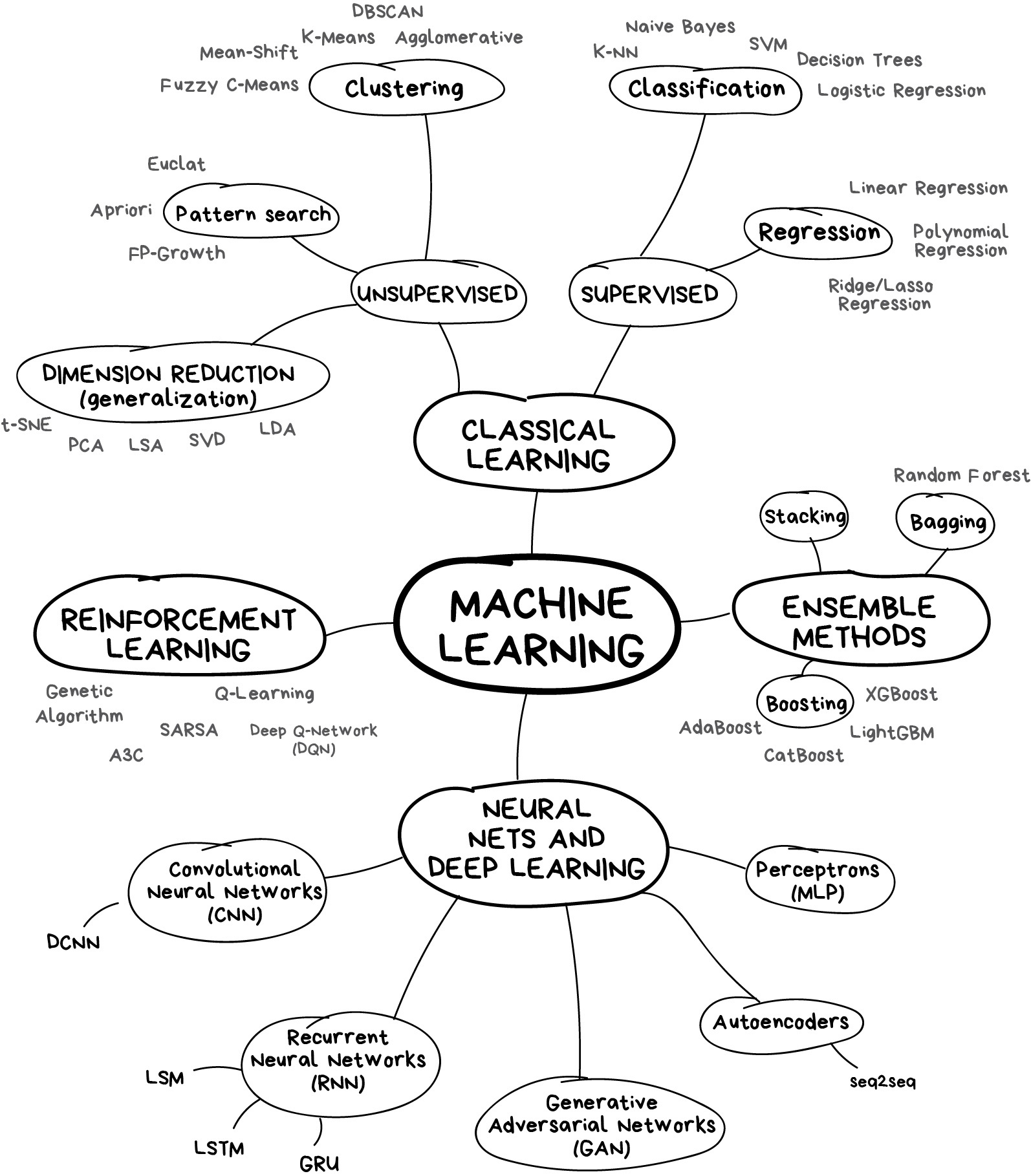
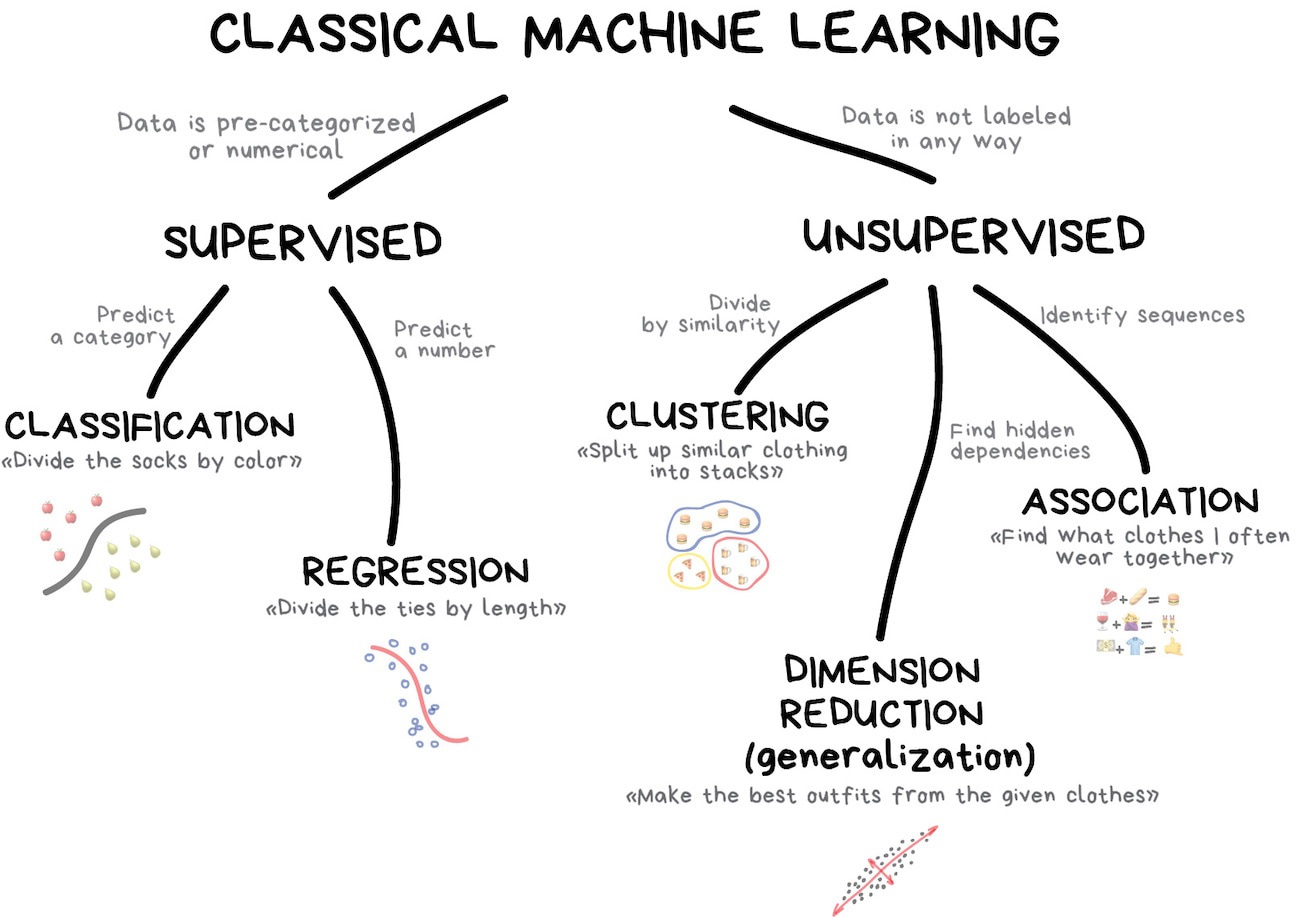
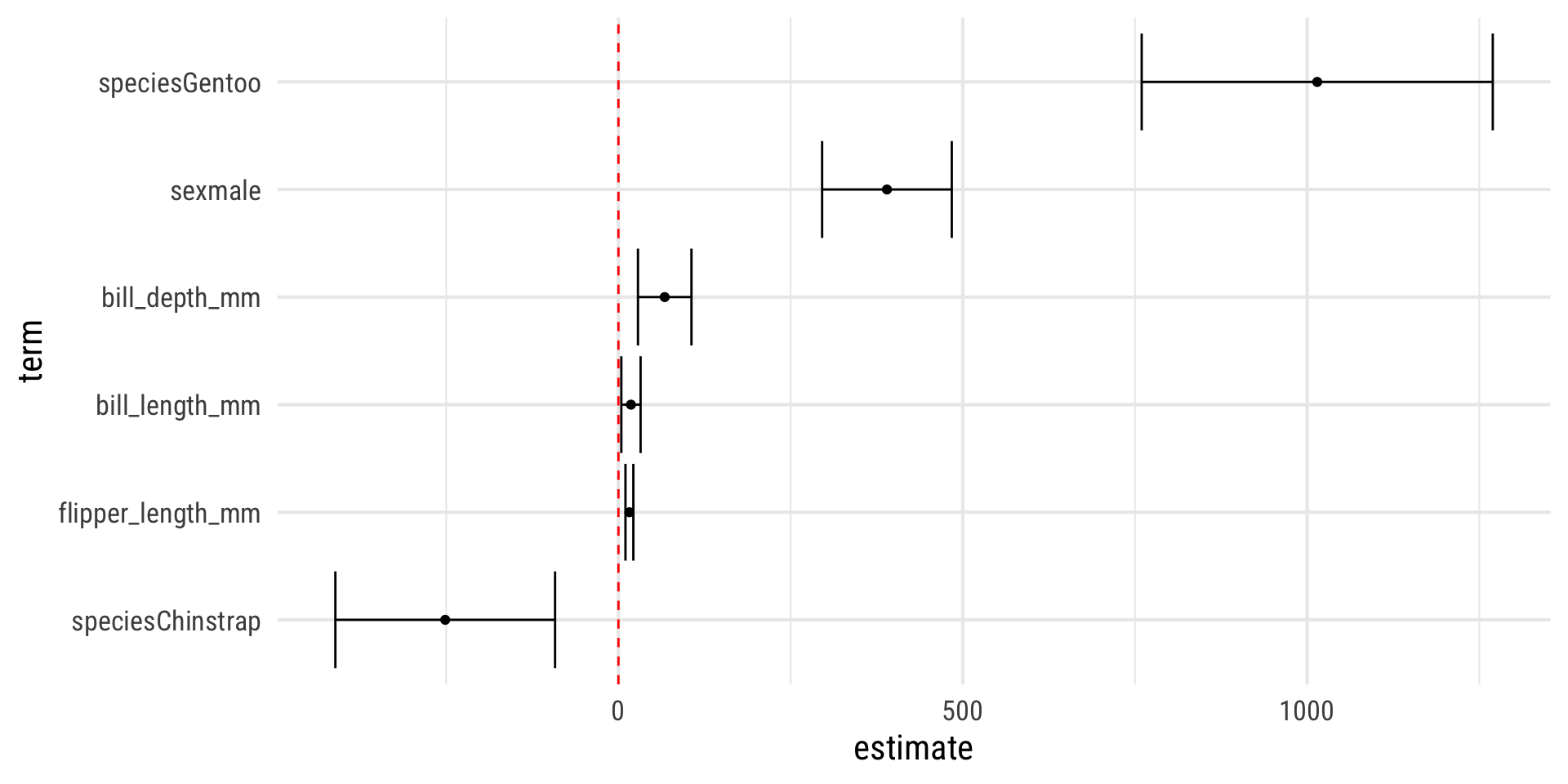
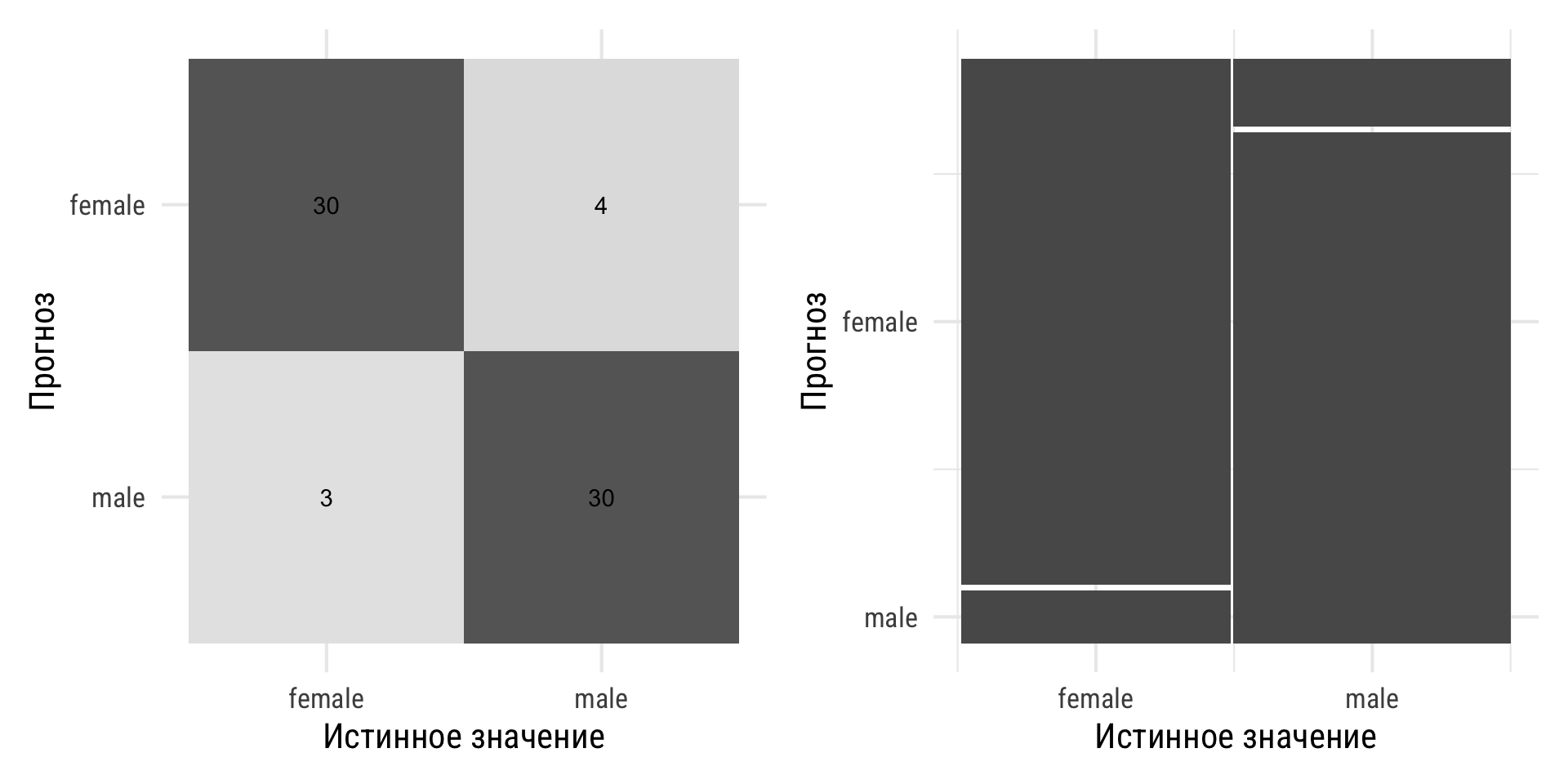
Библиотека {broom} позволяет создавать tidy-таблицы для моделей.
tidy создает таблицу, которая суммирует статистические результаты модели; augment добавляет столбцы к исходным данным, например, прогнозы и остатки; glance строит краткое однострочное резюме модели.
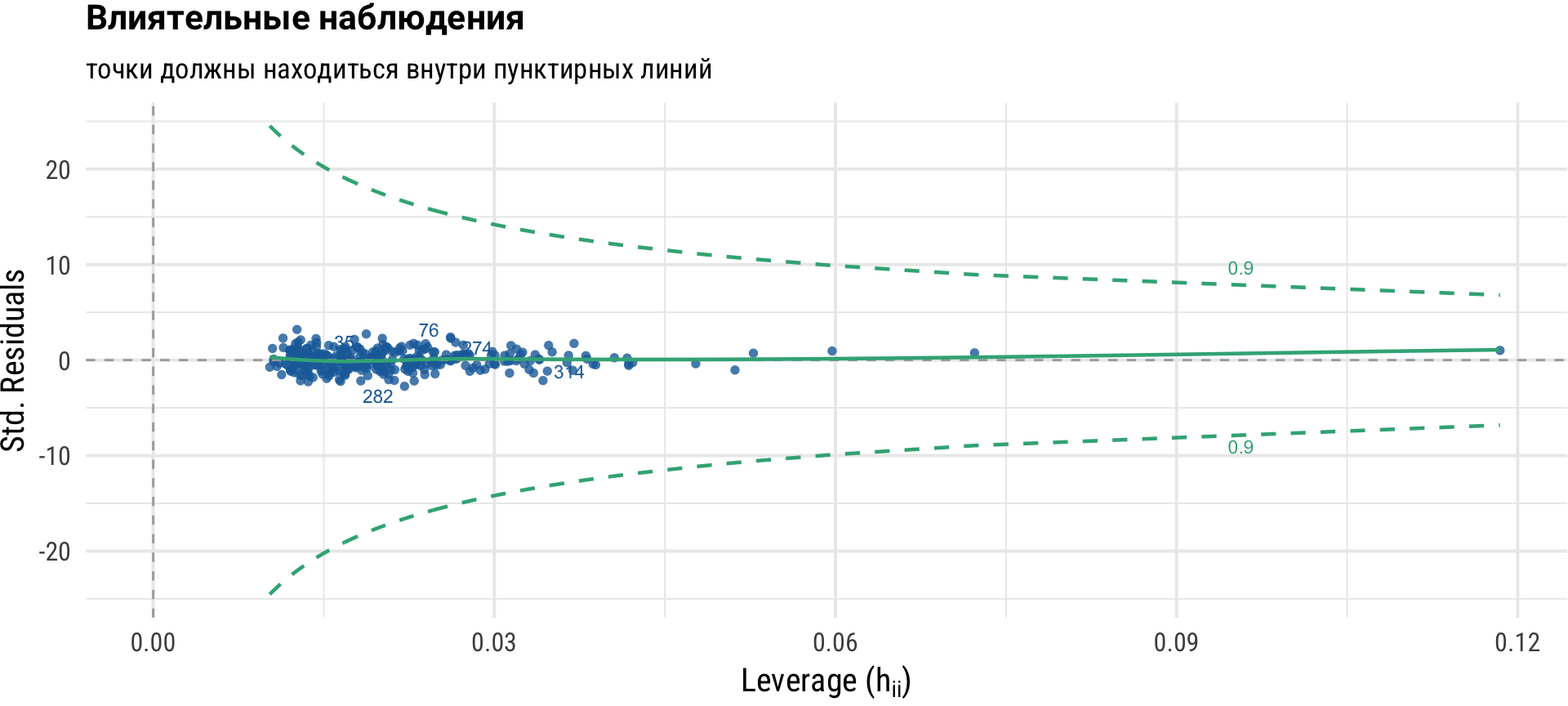
Для диагностики модели можно использовать библиотеку {performance}.
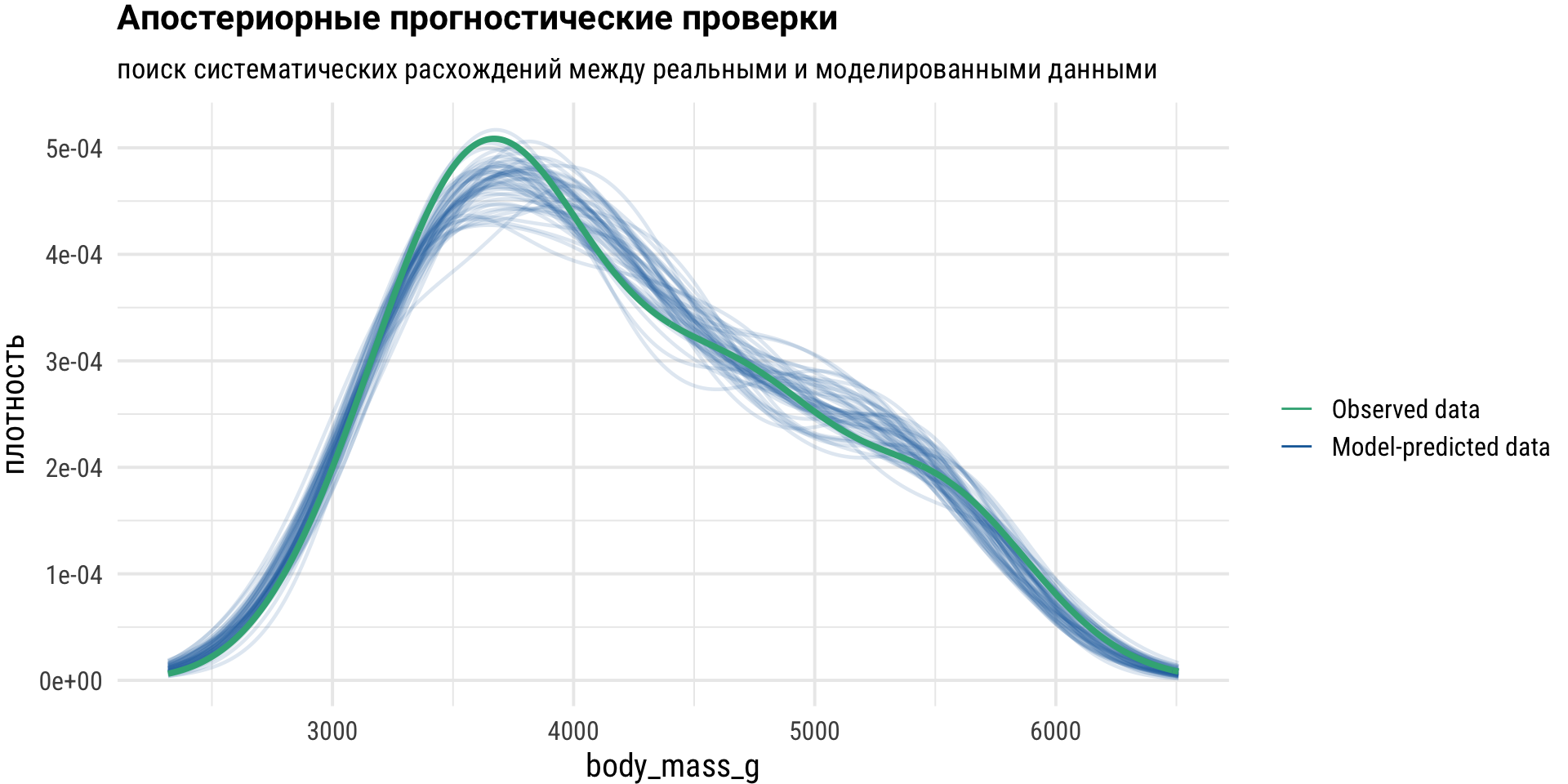
Проверим, соответствует ли тип модели (семейство распределений) исходным данным: линии, предсказанные моделью, должны быть похожи на наблюдаемые линии данных.
Синие линии на следующем графике — это смоделированные данные на основе модели, если бы модель была истинной и распределительные предположения были выполнены.
Зеленая линия представляет фактические наблюдаемые данные переменной отклика.
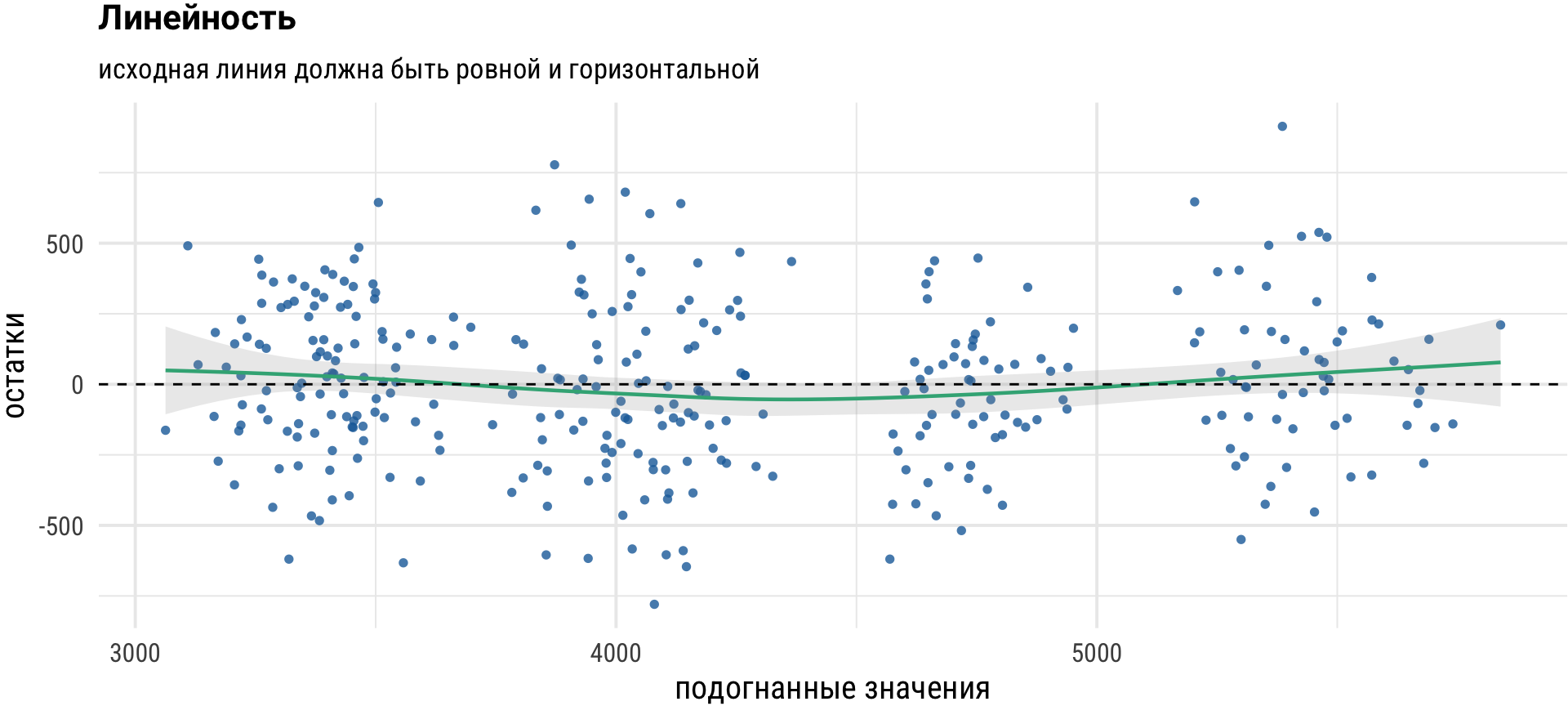
Следующий график помогает проверить могут ли предикторы иметь нелинейную связь с результатом, в этом случае опорная линия может приблизительно указывать на эту связь.
Прямая и горизонтальная линия указывает на то, что спецификация модели в порядке.
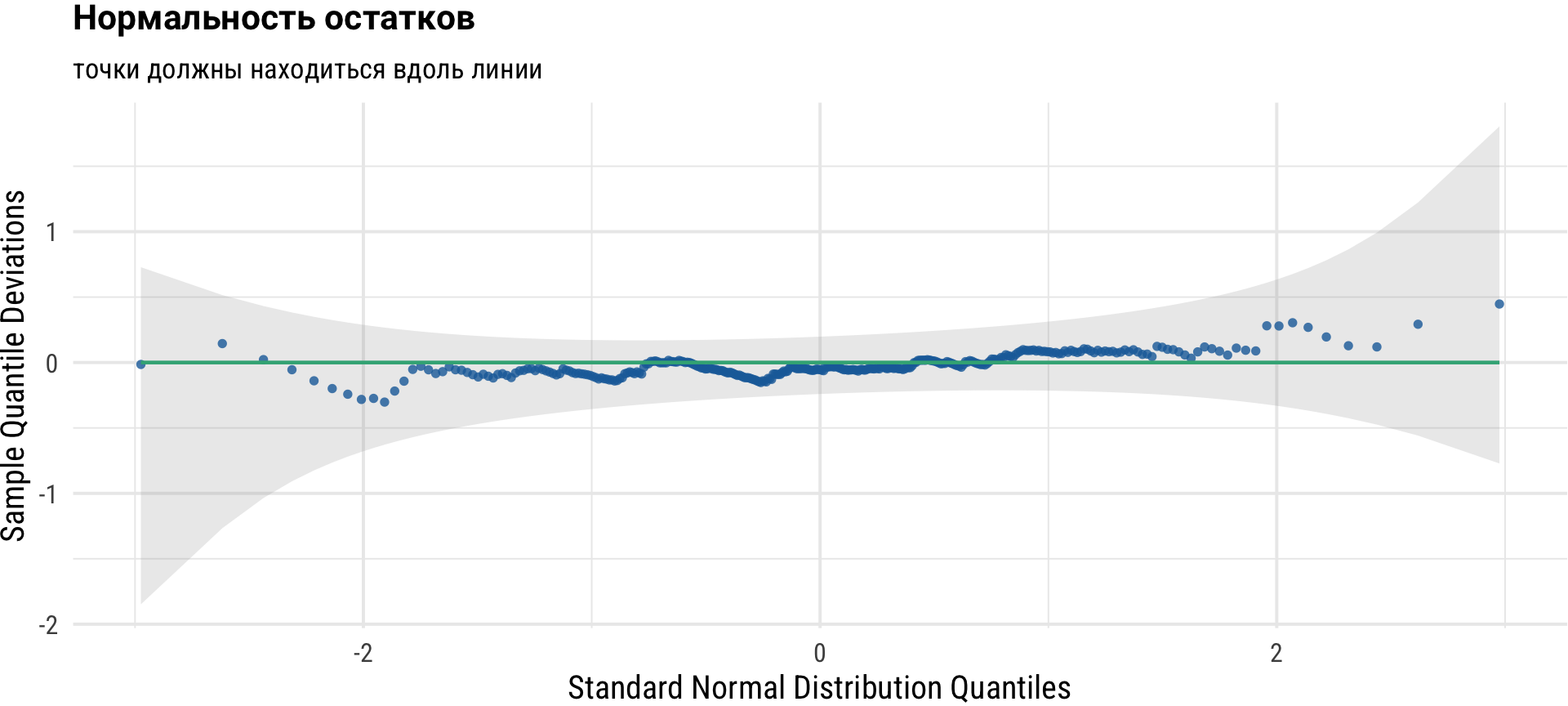
В линейной регрессииостатки должны быть нормально распределены. Данное условие можно проверить с помощью так называемого QQ-графика (квантиль-квантильного графика), который показывает квантили стьюдентизированных остатков по сравнению с подобранными значениями.
Точки должны располагаться вдоль зеленой референтной линии. Если это не происходит, выводные статистики, такие как p-значение или покрытие доверительных интервалов, могут быть неточными.
унифицированный интерфейс для моделей, который позволяет указывать модель без необходимости запоминать различные имена аргументов функций или вычислительных движков
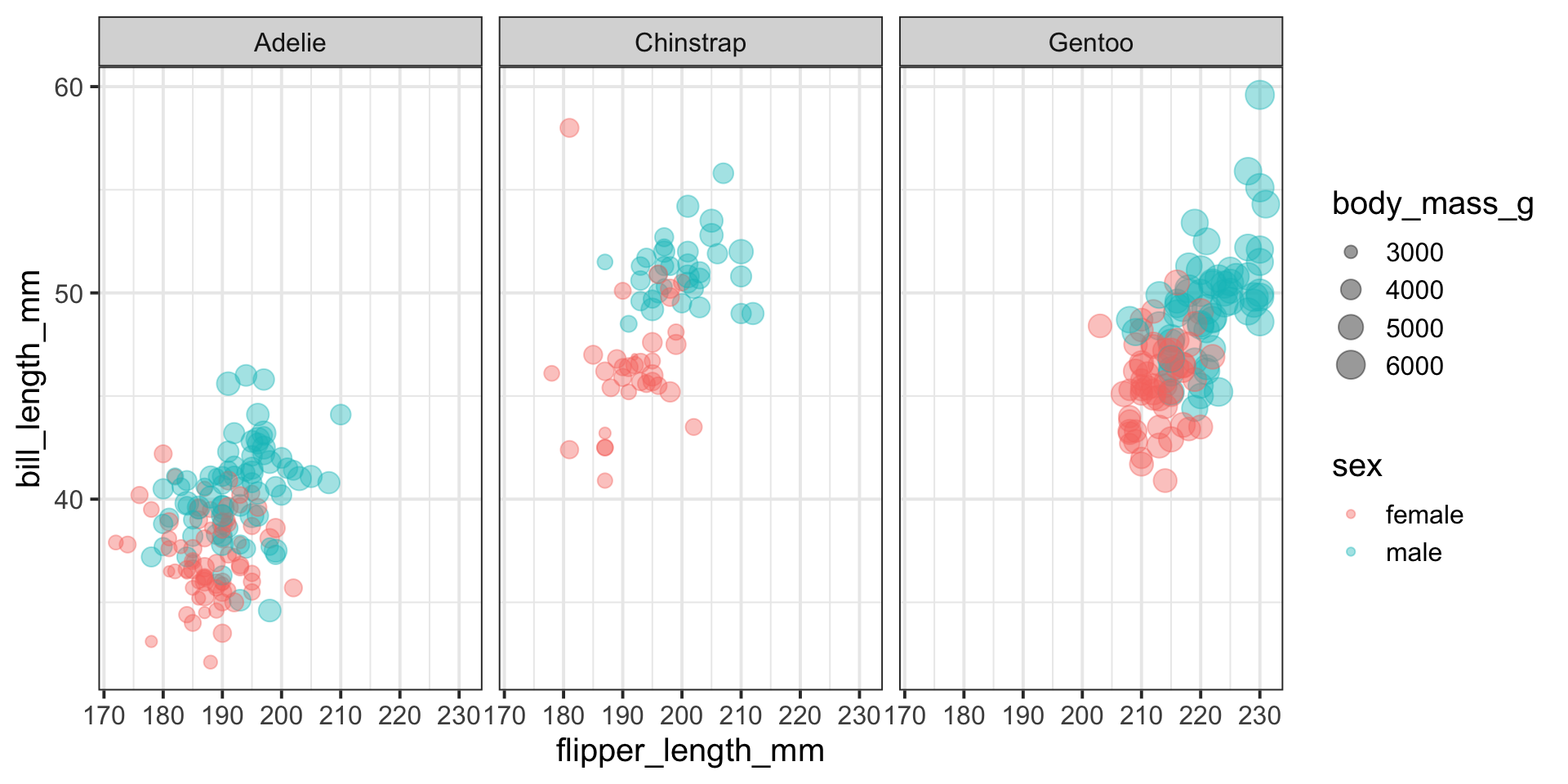
penguins_df |>ggplot(aes(x = flipper_length_mm, y = bill_length_mm, color = sex, size = body_mass_g)) +geom_point(alpha =0.4) +facet_wrap(~species) +theme_bw()
Разбиение на выборки
Ресамплинг состоит в разбиении всей выборки на обучающую и тестовую в библиотеке {rsample}.
strata — переменная для проведения стратифицированного разбиения, это может помочь гарантировать, что повторные выборки имеют эквивалентные пропорции с исходным набором данных.
# задает начальное число для генератора случайных чисел, # что помогает улучшить воспроизводимость кодаset.seed(2025)# разбиениеpenguin_split <-initial_split(penguins_df, strata = sex,prop =0.8)
Инициализируем рецепт в библиотеке {recipes}, используя формулу:
penguin_rec <-recipe(sex ~ ., data = penguin_train)
Формула заявляет, что столбец sex является результатом (так как он находится слева от тильды).
Точка справа указывает, что все столбцы (переменные) в penguin_train, кроме результата, следует рассматривать как предикторы.
Конструирование признаков
Конструирование признаков (Feature engineering) — это процесс выбора, обработки и преобразования необработанных данных в признаки, которые можно использовать в машинном обучении.
penguin_rec <-recipe(sex ~ ., data = penguin_train) |>step_YeoJohnson(all_numeric_predictors()) |>step_normalize(all_numeric_predictors()) |>step_dummy(species)
step_YeoJohnson() — применяет преобразование Йео-Джонсона ко всем числовым предикторам в данных. Это преобразование может помочь нормализовать данные, сделав их более симметричными и уменьшив влияние выбросов.
step_normalize() — нормализует все числовые предикторы, масштабируя данные так, чтобы они имели среднее значение 0 и стандартное отклонение 1.
step_dummy() — создает фиктивные переменные (бинарные переменные, которые используются для представления категориальных переменных) для переменной species.
penguin_rec#> ── Recipe ──────────────────────────────────────────────────────────────────────#> #> ── Inputs#> Number of variables by role#> outcome: 1#> predictor: 5#> #> ── Operations#> • Yeo-Johnson transformation on: all_numeric_predictors()#> • Centering and scaling for: all_numeric_predictors()#> • Dummy variables from: species
summary(penguin_rec)
# A tibble: 6 × 4
variable type role source
<chr> <list> <chr> <chr>
1 species <chr [3]> predictor original
2 bill_length_mm <chr [2]> predictor original
3 bill_depth_mm <chr [2]> predictor original
4 flipper_length_mm <chr [2]> predictor original
5 body_mass_g <chr [2]> predictor original
6 sex <chr [3]> outcome original
Указание модели
Определим модели с помощью библиотеки {parsnip}, указав движок (set_engine) для модели и режим модели (set_mode), если требуется.
rand_forest() создает спецификацию для модели случайного леса
set_engine("ranger") устанавливает движок для модели как ranger, который является реализацией случайных лесов с использованием библиотеки {ranger}
set_mode("classification") устанавливает режим модели как классификация
Рабочий процесс
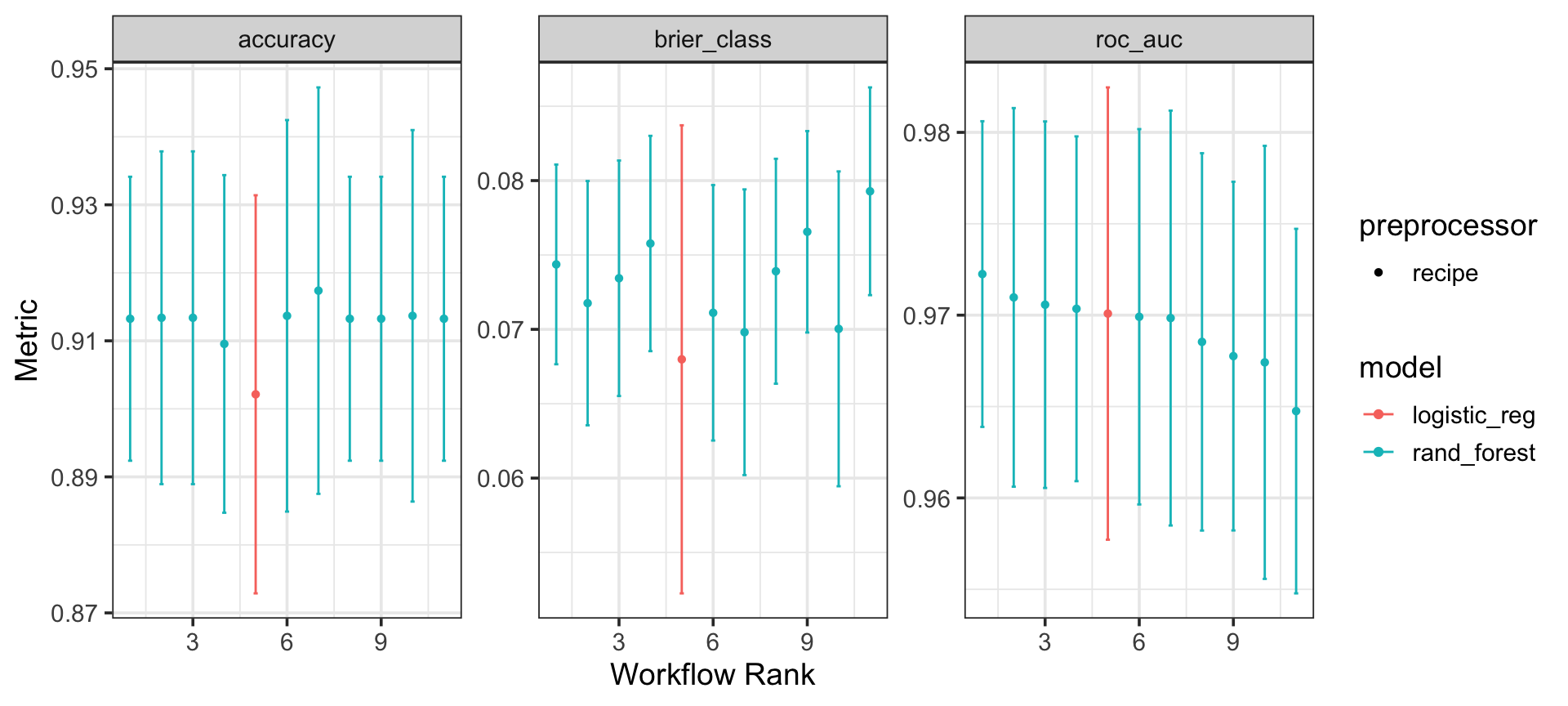
Рабочий процесс объединяет набор моделей и список спецификаций моделирования в аргументе models, workflow_map позволяет указать одни и те же параметры для всех моделей.
# выбор наилучшей моделиbest_model_id <-"recipe_tree"# из workflow_setbest_fit <- workflow_set |>extract_workflow_set_result(best_model_id) |>select_best(metric ="accuracy")# рабочий процесс наилучшей моделиfinal_workflow <- workflow_set |>extract_workflow(best_model_id) |>finalize_workflow(best_fit)
Дообучение модели
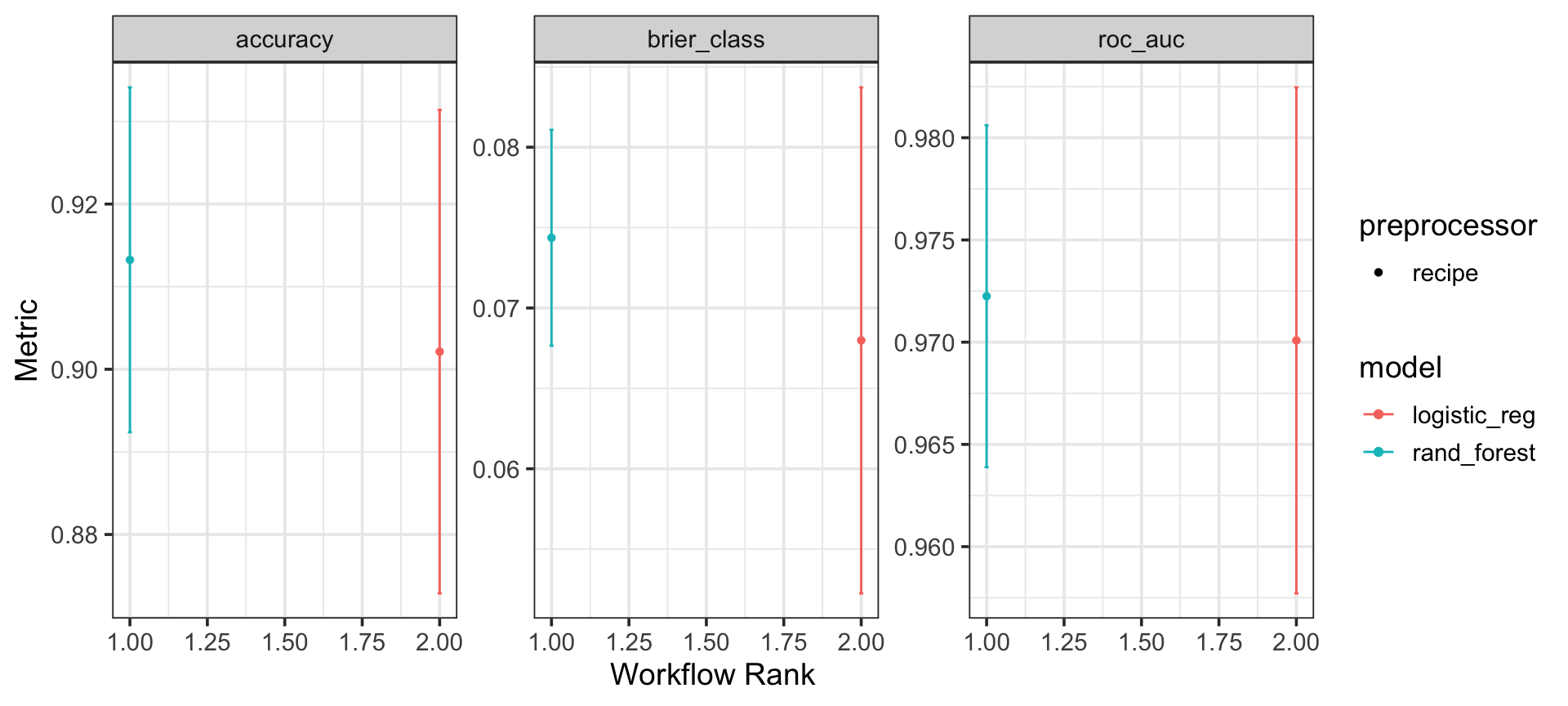
Распространим модель на все данные и сравним метрики.
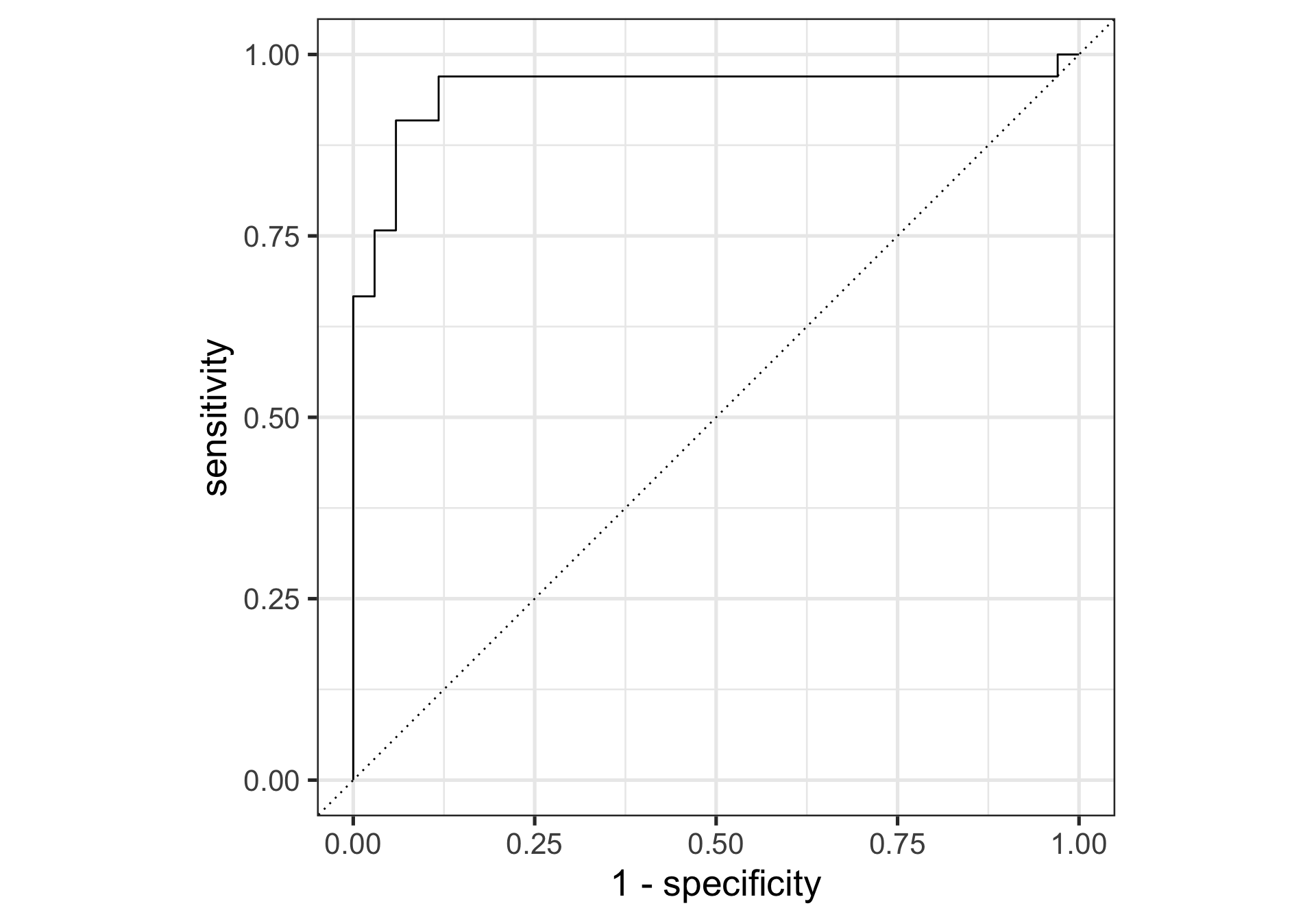
# дообучение на всех данныхfinal_fit <- final_workflow |>last_fit(penguin_split)# финальные метрикиcollect_metrics(final_fit)
brier_class — оценка Брайера аналогичная средней квадратичной ошибке в регрессионных моделях. Разница между бинарным индикатором для класса и его соответствующей вероятностью класса возводится в квадрат и усредняется.
Прогнозирование
Распространим модель на исходное множество.
# модель для исходных данныхfinal_model <-fit(final_workflow, penguins_df)
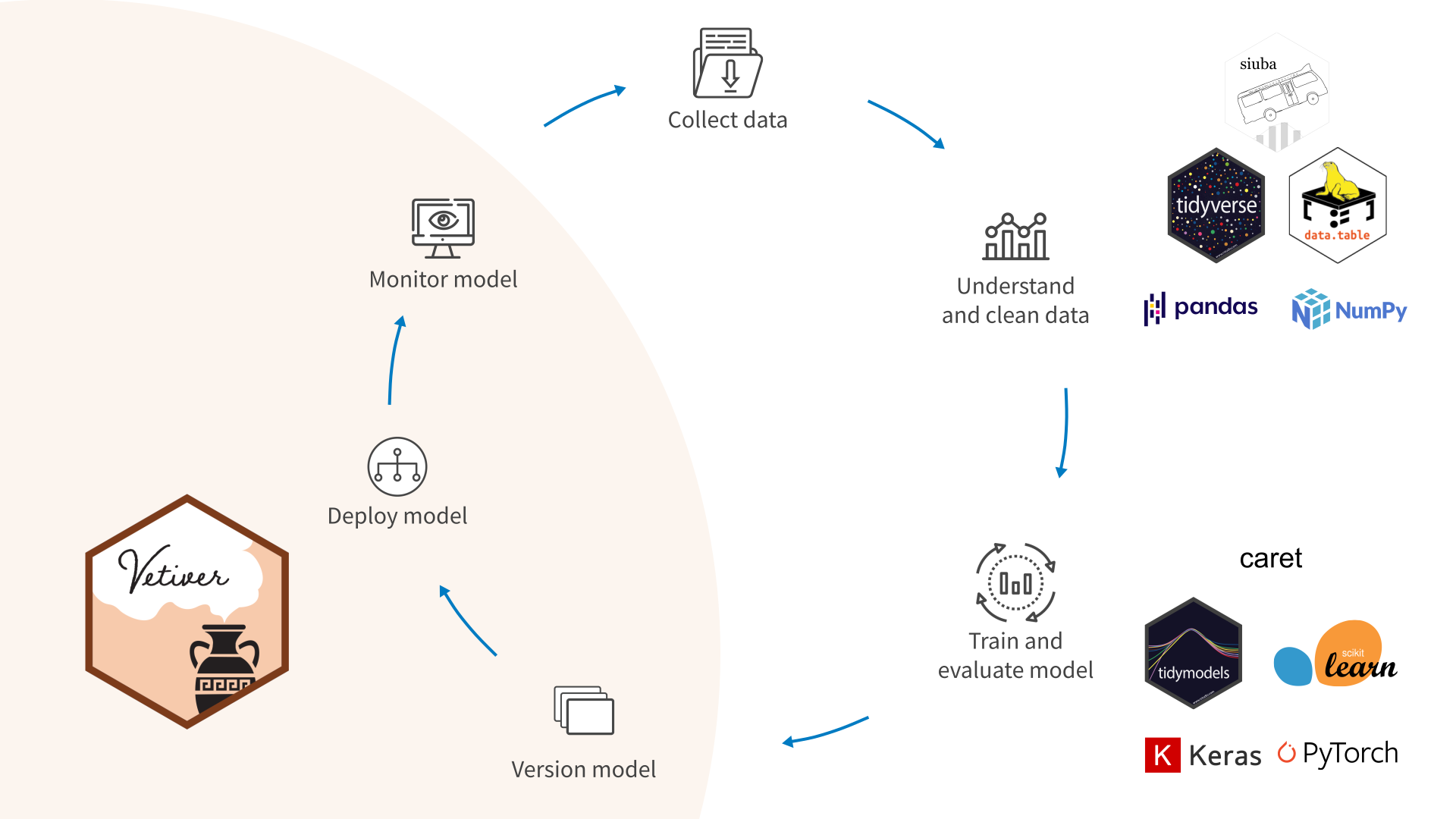
Библиотека {vetiver} предоставляет набор инструментов для создания, развертывания и управления моделями машинного обучения.
Она позволяет пользователям легко создавать, версионировать, развертывать и мониторить модели машинного обучения на различных хостинговых платформах, таких как Posit Connect или облачный хостинговый сервис, такой как Azure.
R in Production (автор Hadley Wickham) дает основы развертывания современных проектов на R.
Развертывание модели
Что мы изучили
Рассмотренные вопросы
Возможности для машинного обучения в R
Диагностика линейной регрессии с помощью broom и performance